はじめに
Zennで投稿した「kaggleでよく使う交差検証テンプレ(Keras向け)」に追記した内容になります。
kaggleでクロスバリデーションをする際に、毎回調べては、毎回少しずつ異なるやり方をしていたので、ここでテンプレとなる型をまとめようと思います。
ここでは、Kerasでのニューラルネットワークモデルを使ったクロスバリデーションとしています。
LightGBMでのクロスバリデーションは以下でまとめています。

kaggleでよく使う交差検証テンプレ(LightGBM向け)
:::affiliate-message 本ページはAmazonアフィリエイトのリンクを含みます。
対象読者
- kaggleでクロスバリデーションを使いたい人
クロスバリデーション(交差検証)とは
まずは、そもそもクロスバリデーションとは何かについて、簡単に説明します。
クロスバリデーション(交差検証)とは、学習用のデータを複数の分割パターンで学習データと検証データに分けてモデルの汎化性能(未知のデータに対する予測能力)を検証することです。
分割した学習データで学習し、検証データで予測し精度を検証します。複数の分割パターンで検証を行うことでより正確なモデルの精度を測ることができます。最終的なテストデータへの予測は、各モデルでの平均とすることが多いです。
分割したデータはfoldと呼ばれます。
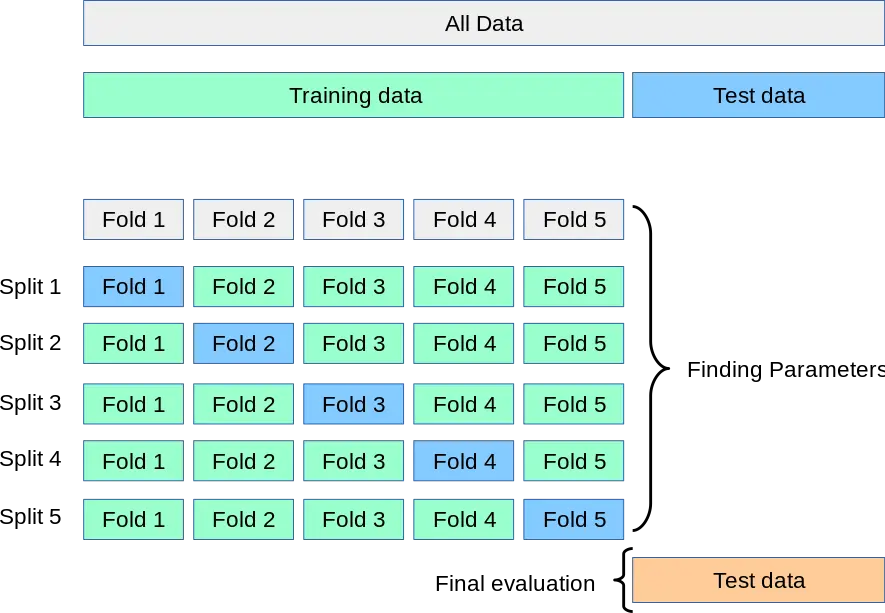 scikit-learnのドキュメントより
scikit-learnのドキュメントより
kaggleでは提出用のテストデータは、PublicとPrivateに分かれており、最終的な順位はPrivateのテストデータで行われます。Publicのスコアが良くても、たまたまPublicのテストデータをうまく予測できていただけの可能性もあるため、Privateになった時に順位が大きく下がってしまうことがあります。そこで、クロスバリデーションのスコアでモデルの精度を検証することで、より正確にモデルの精度を検証することができるようになります。
よく使うクロスバリデーションとテンプレ
具体的なクロスバリデーションの手法とテンプレを紹介していきます。
前提
テンプレの前に、前提となる学習データの変数を定義しておきます。基本的に、前処理などが終わったら以下の形にするようにします。
1"""
2X : numpy.ndarray
3 学習データの特徴量
4y : numpy.ndarray
5 学習データの目的変数
6"""K-fold(k分割交差検証)
最もよく使う基本的なクロスバリデーションです。
学習データをk個に分割し、k-1個分の学習データと1個分の検証データに分けてモデルの汎化性能を検証します。k回学習を繰り返し、分割したデータはそれぞれ1回ずつ検証データとして使います。
最終的にモデルの汎化性能を測る時は、各foldにおけるスコアを平均します。
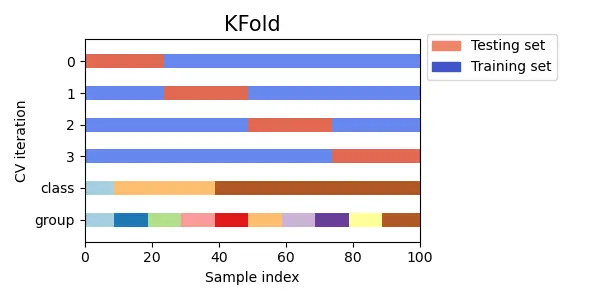 scikit-learnのドキュメントより
scikit-learnのドキュメントより
テンプレ
- scikit-learnの
KFoldを利用 - ニューラルネットワークモデルは
build_modelという関数を用意する - 学習時のコールバックは
ReduceLROnPlateau・ModelCheckpoint・EarlyStopping - 評価関数はMAE
1from sklearn.metrics import mean_absolute_error
2from sklearn.model_selection import KFold
3from tensorflow.keras.callbacks import ReduceLROnPlateau, ModelCheckpoint, EarlyStopping
4import numpy as np
5
6FOLD = 5
7EPOCH = 10
8BATCH_SIZE = 32
9
10valid_scores = []
11models = []
12kf = KFold(n_splits=FOLD, shuffle=True, random_state=42)
13
14for fold, (train_indices, valid_indices) in enumerate(kf.split(X)):
15 X_train, X_valid = X[train_indices], X[valid_indices]
16 y_train, y_valid = y[train_indices], y[valid_indices]
17
18 model = build_model(X_train.shape[1])
19 rlr = ReduceLROnPlateau(monitor='val_loss',
20 factor=0.1,
21 patience=3,
22 verbose=0,
23 min_delta=1e-4,
24 mode='max')
25 ckp = ModelCheckpoint(f'model_{fold}.hdf5',
26 monitor='val_loss',
27 verbose=0,
28 save_best_only=True,
29 save_weights_only=True,
30 mode='max')
31 es = EarlyStopping(monitor='val_loss',
32 min_delta=1e-4,
33 patience=7,
34 mode='max',
35 baseline=None,
36 restore_best_weights=True,
37 verbose=0)
38
39 model.fit(X_train, y_train,
40 validation_data=(X_valid, y_valid),
41 epochs=EPOCH,
42 batch_size=BATCH_SIZE,
43 callbacks=[rlr, ckp, es],
44 verbose=0)
45
46 y_valid_pred = model.predict(X_valid)
47 score = mean_absolute_error(y_valid, y_valid_pred)
48 print(f'fold {fold} MAE: {score}')
49 valid_scores.append(score)
50
51 models.append(model)
52
53cv_score = np.mean(valid_scores)
54print(f'CV score: {cv_score}')Shuffle Split
データ全体からランダムにサンプリングして分割する交差検証です。
K-foldの代替手段として利用でき、ランダムにサンプリングしているため各foldでのデータを重複がありえます。そのため、検証データとして利用されてないデータも出てくる可能性があります。
全体を重複なく分割しているわけではないので、分割数と学習データと検証データの比率を自由に調整することができます。
K-foldでshuffle=Trueのオプションがありますが、これはデータ全体をシャッフルしてから重複なくデータを分割しているので、Shuffle Splitとは異なる結果(分割)になります。
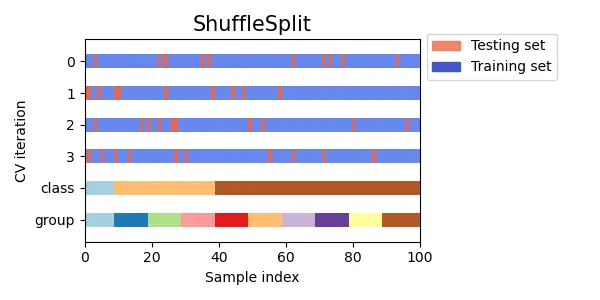 scikit-learnのドキュメントより
scikit-learnのドキュメントより
テンプレ
- scikit-learnの
ShuffleSplitを利用 - ニューラルネットワークモデルは
build_modelという関数を用意する - 学習時のコールバックは
ReduceLROnPlateau・ModelCheckpoint・EarlyStopping - 評価関数はMAE
- 検証データは25%
1from sklearn.metrics import mean_absolute_error
2from sklearn.model_selection import ShuffleSplit
3from tensorflow.keras.callbacks import ReduceLROnPlateau, ModelCheckpoint, EarlyStopping
4import numpy as np
5
6FOLD = 5
7EPOCH = 10
8BATCH_SIZE = 32
9
10valid_scores = []
11models = []
12ss = ShuffleSplit(n_splits=FOLD, test_size=0.25, random_state=42)
13
14for fold, (train_indices, valid_indices) in enumerate(ss.split(X)):
15 X_train, X_valid = X[train_indices], X[valid_indices]
16 y_train, y_valid = y[train_indices], y[valid_indices]
17
18 model = build_model(X_train.shape[1])
19 rlr = ReduceLROnPlateau(monitor='val_loss',
20 factor=0.1,
21 patience=3,
22 verbose=0,
23 min_delta=1e-4,
24 mode='max')
25 ckp = ModelCheckpoint(f'model_{fold}.hdf5',
26 monitor='val_loss',
27 verbose=0,
28 save_best_only=True,
29 save_weights_only=True,
30 mode='max')
31 es = EarlyStopping(monitor='val_loss',
32 min_delta=1e-4,
33 patience=7,
34 mode='max',
35 baseline=None,
36 restore_best_weights=True,
37 verbose=0)
38
39 model.fit(X_train, y_train,
40 validation_data=(X_valid, y_valid),
41 epochs=EPOCH,
42 batch_size=BATCH_SIZE,
43 callbacks=[rlr, ckp, es],
44 verbose=0
45
46 y_valid_pred = model.predict(X_valid)
47 score = mean_absolute_error(y_valid, y_valid_pred)
48 print(f'fold {fold} MAE: {score}')
49 valid_scores.append(score)
50
51 models.append(model)
52
53cv_score = np.mean(valid_scores)
54print(f'CV score: {cv_score}')Stratified k-fold(層化k分割交差検証)
各foldに含まれるクラスの割合を等しくするk分割交差検証です。
分類問題で使用され、テストデータと学習データのクラスの割合が等しいと仮定される時に使用される手法です。多クラス分類問題で、ランダムに分割すると各foldのクラスの割合が偏ってしまうような場合(例えば頻度の少ないクラスがある場合)に重要となってきます。
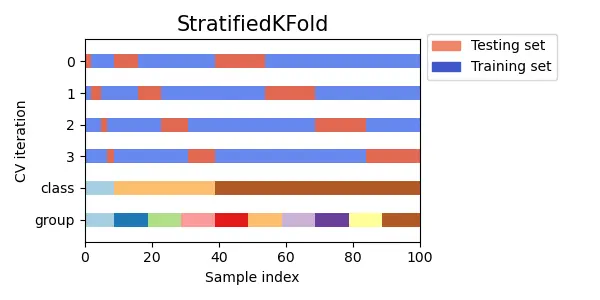 scikit-learnのドキュメントより
scikit-learnのドキュメントより
テンプレ
- scikit-learnの
StratifiedKFoldを利用 - ニューラルネットワークモデルは
build_modelという関数を用意する - 学習時のコールバックは
ReduceLROnPlateau・ModelCheckpoint・EarlyStopping - 評価関数はlog loss
1from sklearn.metrics import log_loss
2from sklearn.model_selection import StratifiedKFold
3from tensorflow.keras.callbacks import ReduceLROnPlateau, ModelCheckpoint, EarlyStopping
4import numpy as np
5
6FOLD = 5
7EPOCH = 10
8BATCH_SIZE = 32
9
10valid_scores = []
11models = []
12kf = StratifiedKFold(n_splits=FOLD, shuffle=True, random_state=42)
13
14for fold, (train_indices, valid_indices) in enumerate(kf.split(X, y)):
15 X_train, X_valid = X[train_indices], X[valid_indices]
16 y_train, y_valid = y[train_indices], y[valid_indices]
17
18 model = build_model(X_train.shape[1])
19 rlr = ReduceLROnPlateau(monitor='val_loss',
20 factor=0.1,
21 patience=3,
22 verbose=0,
23 min_delta=1e-4,
24 mode='max')
25 ckp = ModelCheckpoint(f'model_{fold}.hdf5',
26 monitor='val_loss',
27 verbose=0,
28 save_best_only=True,
29 save_weights_only=True,
30 mode='max')
31 es = EarlyStopping(monitor='val_loss',
32 min_delta=1e-4,
33 patience=7,
34 mode='max',
35 baseline=None,
36 restore_best_weights=True,
37 verbose=0)
38
39 model.fit(X_train, y_train,
40 validation_data=(X_valid, y_valid),
41 epochs=EPOCH,
42 batch_size=BATCH_SIZE,
43 callbacks=[rlr, ckp, es],
44 verbose=0)
45
46 y_valid_pred = model.predict(X_valid)
47 score = log_loss(y_valid, y_valid_pred)
48 print(f'fold {fold} log loss: {score}')
49 valid_scores.append(score)
50
51 models.append(model)
52
53cv_score = np.mean(valid_scores)
54print(f'CV score: {cv_score}')Stratified Shuffle Split
Stratified k-foldのShuffle Split版になります。
クラスの割合を保ったままShuffle Splitをおこないます。Shuffle Split同様、検証データにならないデータがある可能性があります。
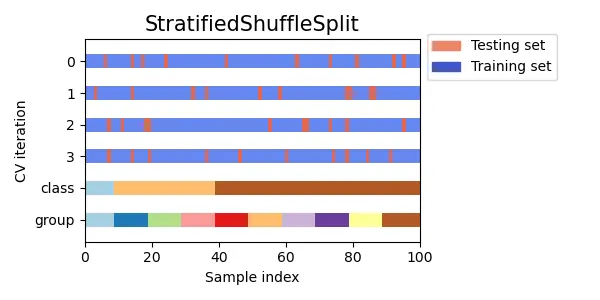 scikit-learnのドキュメントより
scikit-learnのドキュメントより
テンプレ
- scikit-learnの
StratifiedShuffleSplitを利用 - ニューラルネットワークモデルは
build_modelという関数を用意する - 学習時のコールバックは
ReduceLROnPlateau・ModelCheckpoint・EarlyStopping - 評価関数はlog loss
- 検証データは25%
1from sklearn.metrics import log_loss
2from sklearn.model_selection import StratifiedShuffleSplit
3from tensorflow.keras.callbacks import ReduceLROnPlateau, ModelCheckpoint, EarlyStopping
4import numpy as np
5
6FOLD = 5
7EPOCH = 10
8BATCH_SIZE = 32
9
10valid_scores = []
11models = []
12sss = StratifiedShuffleSplit(n_splits=FOLD, test_size=0.25, random_state=42)
13
14for fold, (train_indices, valid_indices) in enumerate(sss.split(X, y)):
15 X_train, X_valid = X[train_indices], X[valid_indices]
16 y_train, y_valid = y[train_indices], y[valid_indices]
17
18 model = build_model(X_train.shape[1])
19 rlr = ReduceLROnPlateau(monitor='val_loss',
20 factor=0.1,
21 patience=3,
22 verbose=0,
23 min_delta=1e-4,
24 mode='max')
25 ckp = ModelCheckpoint(f'model_{fold}.hdf5',
26 monitor='val_loss',
27 verbose=0,
28 save_best_only=True,
29 save_weights_only=True,
30 mode='max')
31 es = EarlyStopping(monitor='val_loss',
32 min_delta=1e-4,
33 patience=7,
34 mode='max',
35 baseline=None,
36 restore_best_weights=True,
37 verbose=0)
38
39 model.fit(X_train, y_train,
40 validation_data=(X_valid, y_valid),
41 epochs=EPOCH,
42 batch_size=BATCH_SIZE,
43 callbacks=[rlr, ckp, es],
44 verbose=0)
45
46 y_valid_pred = model.predict(X_valid)
47 score = log_loss(y_valid, y_valid_pred)
48 print(f'fold {fold} log loss: {score}')
49 valid_scores.append(score)
50
51 models.append(model)
52
53cv_score = np.mean(valid_scores)
54print(f'CV score: {cv_score}')Group k-fold(グループk分割交差検証)
同じグループ(顧客や被験者など特定の人物を表すものなど)が同じfoldになるようにデータを分割するk分割交差検証です。
テストデータで学習データのグループが現れないような場合に利用します。つまり、未知のグループを予測するような問題であるため、同じグループが異なるfoldに存在してしまうと、検証データにそのグループが含まれている時に予測しやすくなってしまい、適切な検証ができなくなってしまいます。
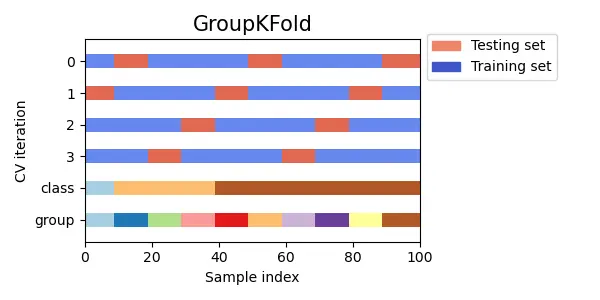 scikit-learnのドキュメントより
scikit-learnのドキュメントより
テンプレ
- scikit-learnの
GroupKFoldを利用- GroupKFoldはシャッフルと乱数の指定ができない
- ニューラルネットワークモデルは
build_modelという関数を用意する - 学習時のコールバックは
ReduceLROnPlateau・ModelCheckpoint・EarlyStopping - 評価関数はMAE
1from sklearn.metrics import mean_absolute_error
2from sklearn.model_selection import GroupKFold
3from tensorflow.keras.callbacks import ReduceLROnPlateau, ModelCheckpoint, EarlyStopping
4import numpy as np
5
6FOLD = 5
7EPOCH = 10
8BATCH_SIZE = 32
9
10group = train['id']
11valid_scores = []
12models = []
13kf = GroupKFold(n_splits=FOLD)
14
15for fold, (train_indices, valid_indices) in enumerate(kf.split(X, y, group)):
16 X_train, X_valid = X[train_indices], X[valid_indices]
17 y_train, y_valid = y[train_indices], y[valid_indices]
18
19 model = build_model(X_train.shape[1])
20 rlr = ReduceLROnPlateau(monitor='val_loss',
21 factor=0.1,
22 patience=3,
23 verbose=0,
24 min_delta=1e-4,
25 mode='max')
26 ckp = ModelCheckpoint(f'model_{fold}.hdf5',
27 monitor='val_loss',
28 verbose=0,
29 save_best_only=True,
30 save_weights_only=True,
31 mode='max')
32 es = EarlyStopping(monitor='val_loss',
33 min_delta=1e-4,
34 patience=7,
35 mode='max',
36 baseline=None,
37 restore_best_weights=True,
38 verbose=0)
39
40 model.fit(X_train, y_train,
41 validation_data=(X_valid, y_valid),
42 epochs=EPOCH,
43 batch_size=BATCH_SIZE,
44 callbacks=[rlr, ckp, es],
45 verbose=0)
46
47 y_valid_pred = model.predict(X_valid)
48 score = mean_absolute_error(y_valid, y_valid_pred)
49 print(f'fold {fold} MAE: {score}')
50 valid_scores.append(score)
51
52 models.append(model)
53
54cv_score = np.mean(valid_scores)
55print(f'CV score: {cv_score}')Group Shuffle Split
Group k-foldのShuffle Split版になります。
検証データで学習データのグループが現れないようにShuffle Splitをおこないます。Shuffle Split同様、検証データにならないデータがある可能性があります。
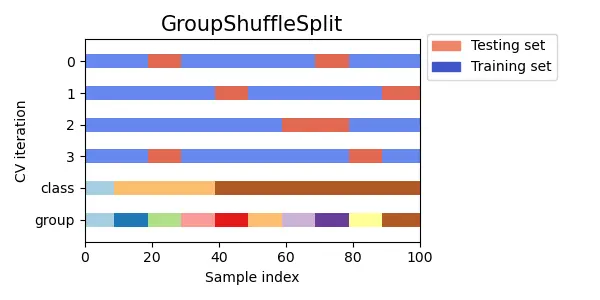 scikit-learnのドキュメントより
scikit-learnのドキュメントより
テンプレ
- scikit-learnの
GroupShuffleSplitを利用 - ニューラルネットワークモデルは
build_modelという関数を用意する - 学習時のコールバックは
ReduceLROnPlateau・ModelCheckpoint・EarlyStopping - 評価関数はMAE
- 検証データは25%
1from sklearn.metrics import mean_absolute_error
2from sklearn.model_selection import GroupShuffleSplit
3from tensorflow.keras.callbacks import ReduceLROnPlateau, ModelCheckpoint, EarlyStopping
4import numpy as np
5
6FOLD = 5
7EPOCH = 10
8BATCH_SIZE = 32
9
10group = train['id']
11valid_scores = []
12models = []
13gss = GroupShuffleSplit(n_splits=FOLD, test_size=0.25, random_state=42)
14
15for fold, (train_indices, valid_indices) in enumerate(gss.split(X, y, group)):
16 X_train, X_valid = X[train_indices], X[valid_indices]
17 y_train, y_valid = y[train_indices], y[valid_indices]
18
19 model = build_model(X_train.shape[1])
20 rlr = ReduceLROnPlateau(monitor='val_loss',
21 factor=0.1,
22 patience=3,
23 verbose=0,
24 min_delta=1e-4,
25 mode='max')
26 ckp = ModelCheckpoint(f'model_{fold}.hdf5',
27 monitor='val_loss',
28 verbose=0,
29 save_best_only=True,
30 save_weights_only=True,
31 mode='max')
32 es = EarlyStopping(monitor='val_loss',
33 min_delta=1e-4,
34 patience=7,
35 mode='max',
36 baseline=None,
37 restore_best_weights=True,
38 verbose=0)
39
40 model.fit(X_train, y_train,
41 validation_data=(X_valid, y_valid),
42 epochs=EPOCH,
43 batch_size=BATCH_SIZE,
44 callbacks=[rlr, ckp, es],
45 verbose=0)
46
47 y_valid_pred = model.predict(X_valid)
48 score = mean_absolute_error(y_valid, y_valid_pred)
49 print(f'fold {fold} MAE: {score}')
50 valid_scores.append(score)
51
52 models.append(model)
53
54cv_score = np.mean(valid_scores)
55print(f'CV score: {cv_score}')実践してみる
実際にscikit-learnのデータセットであるbostonデータを使ってクロスバリデーションを実施してみます。
1from sklearn.datasets import load_boston
2from sklearn.metrics import mean_absolute_error
3from sklearn.model_selection import KFold, train_test_split
4from tensorflow.keras.callbacks import ReduceLROnPlateau, ModelCheckpoint, EarlyStopping
5from tensorflow.keras.layers import Dense
6from tensorflow.keras.models import Sequential
7
8import numpy as np
9
10# データの読み込み
11boston = load_boston()
12X, X_test, y, y_test = train_test_split(
13 boston['data'], boston['target'], test_size=0.3, random_state=0)
14
15
16# モデルの構築
17def build_model(n_features):
18 model = Sequential()
19 model.add(Dense(64, activation='relu', input_shape=(n_features,)))
20 model.add(Dense(64, activation='relu'))
21 model.add(Dense(1))
22 model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
23 return model
24
25
26# k-fold cross validation
27FOLD = 5
28EPOCH = 10
29BATCH_SIZE = 32
30
31valid_scores = []
32models = []
33kf = KFold(n_splits=FOLD, shuffle=True, random_state=42)
34
35for fold, (train_indices, valid_indices) in enumerate(kf.split(X)):
36 X_train, X_valid = X[train_indices], X[valid_indices]
37 y_train, y_valid = y[train_indices], y[valid_indices]
38
39 model = build_model(X_train.shape[1])
40 rlr = ReduceLROnPlateau(monitor='val_loss',
41 factor=0.1,
42 patience=3,
43 verbose=0,
44 min_delta=1e-4,
45 mode='max')
46 ckp = ModelCheckpoint(f'model_{fold}.hdf5',
47 monitor='val_loss',
48 verbose=0,
49 save_best_only=True,
50 save_weights_only=True,
51 mode='max')
52 es = EarlyStopping(monitor='val_loss',
53 min_delta=1e-4,
54 patience=7,
55 mode='max',
56 baseline=None,
57 restore_best_weights=True,
58 verbose=0)
59
60 model.fit(X_train, y_train,
61 validation_data=(X_valid, y_valid),
62 epochs=EPOCH,
63 batch_size=BATCH_SIZE,
64 callbacks=[rlr, ckp, es],
65 verbose=0)
66
67 y_valid_pred = model.predict(X_valid)
68 score = mean_absolute_error(y_valid, y_valid_pred)
69 print(f'fold {fold} MAE: {score}')
70 valid_scores.append(score)
71
72 models.append(model)
73
74
75cv_score = np.mean(valid_scores)
76print(f'CV score: {cv_score}')
77
78# テストデータの予測
79preds = []
80for model in models:
81 pred = model.predict(X_test)
82 preds.append(pred)
83
84y_pred = np.mean(preds, axis=0)
85print(f'Test Score MAE: {mean_absolute_error(y_pred, y_test)}')出力結果は以下のようになります。
1fold 0 MAE: 4.701173231635296
2fold 1 MAE: 10.668852969962106
3fold 2 MAE: 11.41734183405487
4fold 3 MAE: 8.52358005953507
5fold 4 MAE: 5.542828990391323
6CV score: 8.170755417115732
7Test Score MAE: 5.843269380142814まとめ
今回は、以下のクロスバリデーションのテンプレを用意しました。
- K Fold
- Shuffle Split
- Stratified K Fold
- Stratified Shuffle Split
- Group K Fold
- Group Shuffle Split
ただし、なんでもこの6つでいいというわけではないので、問題によって適切なクロスバリデーションの手法を選択するのが重要になります。。
参考
- API Reference — scikit-learn 0.24.0 documentation
- 3.1. Cross-validation: evaluating estimator performance — scikit-learn 0.24.1 documentation
- Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~ - Qiita



\ この記事が役に立ったと思ったら、サポートお願いします! /

関連記事

Keras Tunerでハイパーパラメータチューニング

【kaggle】TabNetの使い方

kaggleでよく使う交差検証テンプレ(LightGBM向け)

