はじめに
最近kaggleでよく目にするTabNetについて、簡単にどんなものなのか、どうやって使うのかについて紹介していきます。
どんなもの何かについては簡単に紹介し、どうやって使うかをメインで紹介していきます。
TabNetとは
TabNetとは、テーブルデータに対して高精度かつ解釈可能なニューラルネットワークモデルになります。最近ではkaggleでもよく使われています。
下記の画像のように、事前にマスクされた特徴量を予測するような教師なし学習をし、学習モデルに適用することで予測の精度を向上させています。
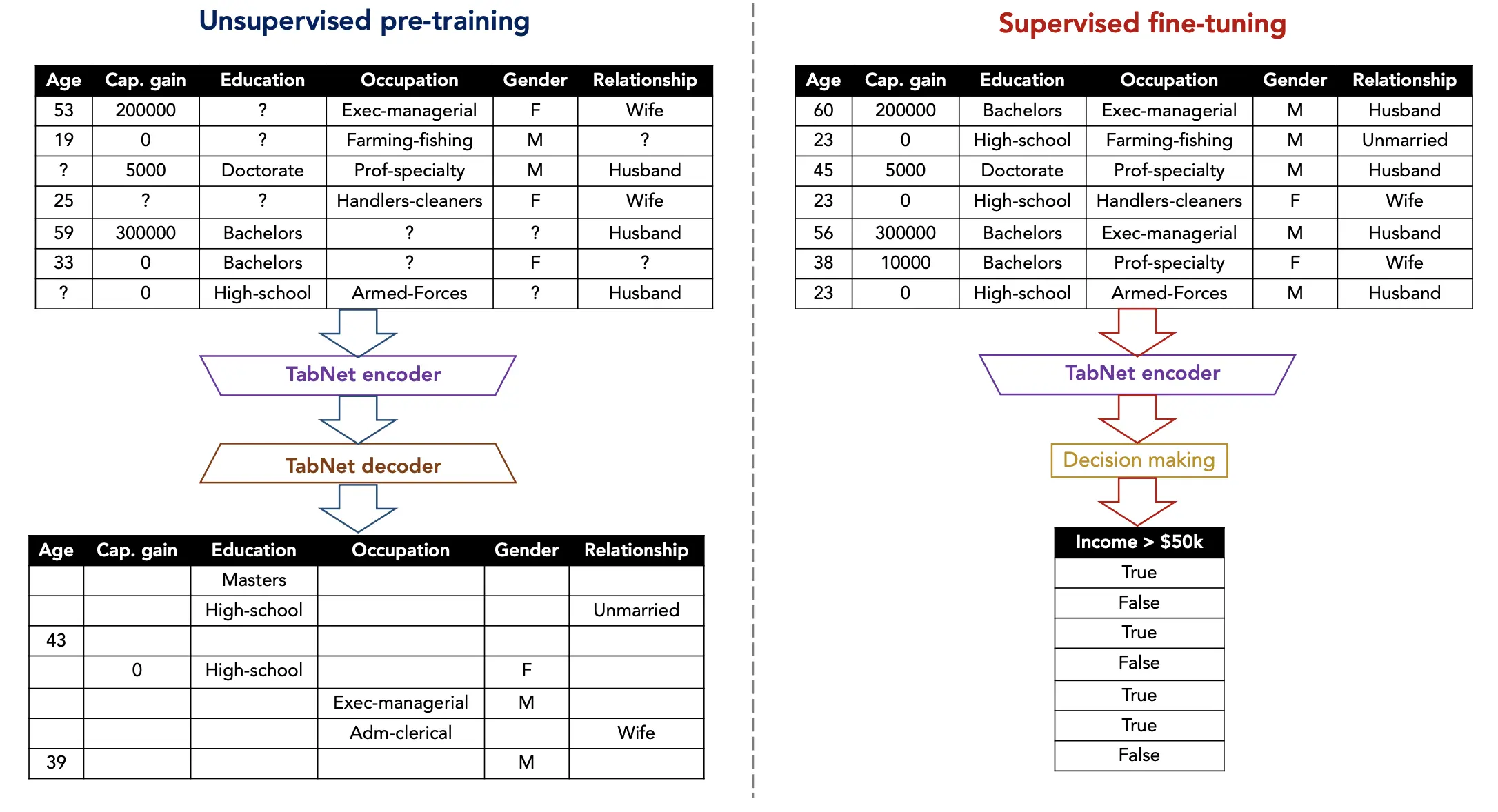 論文より
論文より
また、予測したモデルでの特徴量の重要度もわかるようになっています。
論文は以下になります。
unknown link基本的な使い方
TabNetを利用する場合は下記のリポジトリがよく使われるので、こちらの使い方について紹介していきます。
GitHub - dreamquark-ai/tabnet: PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf
PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf - dreamquark-ai/tabnet
分類問題
分類問題はTabNetClassifierを利用します。
1from pytorch_tabnet.tab_model import TabNetClassifier
2
3model = TabNetClassifier()
4model.fit(
5 X_train, Y_train,
6 eval_set=[(X_valid, y_valid)]
7)
8preds = model.predict(X_test)回帰問題
回帰問題はTabNetRegressorを利用します。
1from pytorch_tabnet.tab_model import TabNetRegressor
2
3model = TabNetRegressor()
4model.fit(
5 X_train, Y_train,
6 eval_set=[(X_valid, y_valid)]
7)
8preds = model.predict(X_test)評価関数のカスタマイズ
以下の評価関数はデフォルトで利用できますが、それ以外のものは自分でカスタマイズする必要があります。
- 二値分類 : 'auc', 'accuracy', 'balanced_accuracy', 'logloss'
- 多クラス分類 : 'accuracy', 'balanced_accuracy', 'logloss'
- 回帰 : 'mse', 'mae', 'rmse', 'rmsle'
カスタマイズする場合は、以下のような評価関数用のクラスを作成し、学習時のパラメータとして設定します。
1from pytorch_tabnet.metrics import Metric
2from sklearn.metrics import f1_score
3
4# 評価関数用のクラス
5class F1ScoreMacro(Metric):
6 def __init__(self):
7 self._name = "f1_score_macro"
8 self._maximize = True
9
10 def __call__(self, y_true, y_pred):
11 f1score = f1_score(y_true, np.argmax(y_pred, axis=1), average='macro')
12 return f1score
13
14model = TabNetClassifier()
15model.fit(
16 X_train, Y_train,
17 eval_set=[(X_valid, y_valid)],
18 eval_metric=[F1ScoreMacro] # 作成した関数の設定
19)事前学習
事前の教師なし学習はTabNetPretrainerでできます。
事前学習したモデルをfrom_unsupervisedパラメータで指定します。
1# 事前学習モデル
2unsupervised_model = TabNetPretrainer(
3 optimizer_fn=torch.optim.Adam,
4 optimizer_params=dict(lr=2e-2),
5 mask_type='entmax'
6)
7
8unsupervised_model.fit(
9 X_train=X_train,
10 eval_set=[X_valid],
11 pretraining_ratio=0.8,
12)
13
14model = TabNetClassifier(
15 optimizer_fn=torch.optim.Adam,
16 optimizer_params=dict(lr=2e-2),
17 scheduler_params={"step_size":10,
18 "gamma":0.9},
19 scheduler_fn=torch.optim.lr_scheduler.StepLR,
20 mask_type='sparsemax'
21)
22
23model.fit(
24 X_train=X_train, y_train=y_train,
25 eval_set=[(X_train, y_train), (X_valid, y_valid)],
26 eval_name=['train', 'valid'],
27 eval_metric=['auc'],
28 from_unsupervised=unsupervised_model # 事前学習したモデルの指定
29)パラメータ
モデルと学習時にパラメータが設定できます。
各種パラメータはリポジトリのREADMEにまとめられています。
GitHub - dreamquark-ai/tabnet: PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf
PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf - dreamquark-ai/tabnet
GitHub - dreamquark-ai/tabnet: PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf
PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf - dreamquark-ai/tabnet
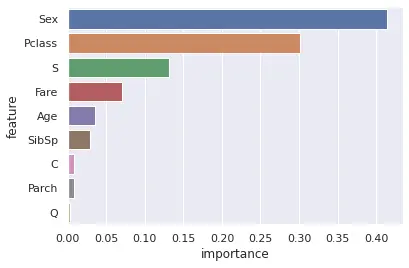
特徴量の重要度
学習後の特徴量ごとの重要度は下記で取得できます。
1model.feature_importances_seabornなどを利用することで各特徴量の重要度を可視化できます。
titanicコンペで実践
実際にkaggleのtitanicコンペでTabNetを利用してみました。

Titanic - Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
Notebookは公開しています。スコアは0.78229となりました。

Titanic: How to use TabNet
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
参考
- 1908.07442.pdf
- dreamquark-ai/tabnet: PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf
\ この記事が役に立ったと思ったら、サポートお願いします! /

関連記事

手軽にデータ分析ができるdablを使ってみた

Keras Tunerでハイパーパラメータチューニング

kaggleでよく使う交差検証テンプレ(LightGBM向け)

