はじめに
こちらの記事はZennで投稿した「手軽にデータ分析ができるdablを使ってみた」の再投稿になります。
kaggleでdablというライブラリが使われていたので、どんなことができるのか実際に使ってみたいと思います。
dablとは
dablは、教師あり学習における予測モデルを構築するまでの基本的なタスクを自動で行ってくれるライブラリです。dablという名称はData Analysis Baseline Libraryの略称となっています。
できること
主にできることは以下の3つです。
- データのクリーニング
- 可視化
- モデルの学習
特に、可視化は複数のグラフを表示してくれるため、「とりあえず可視化するか」ぐらいの時に有用かと思いました。
インストール
まずはインストールします。
1pip install dabl使ってみる
ここからは、kaggleのデータを使いながらdablを実際に使ってみます。
利用データ
利用するのはHouse Pricesコンペのデータです。 79個の特徴量から住宅の価格を予測する回帰問題になります。
まずはデータを読み込みます。
1import pandas as pd
2train = pd.read_csv("../input/house-prices-advanced-regression-techniques/train.csv")読み込んだデータは以下のようになります。
1train.head()| Id | MSSubClass | MSZoning | LotFrontage | LotArea | Street | Alley | LotShape | LandContour | Utilities | LotConfig | LandSlope | Neighborhood | Condition1 | Condition2 | BldgType | HouseStyle | OverallQual | OverallCond | YearBuilt | YearRemodAdd | RoofStyle | RoofMatl | Exterior1st | Exterior2nd | MasVnrType | MasVnrArea | ExterQual | ExterCond | Foundation | BsmtQual | BsmtCond | BsmtExposure | BsmtFinType1 | BsmtFinSF1 | BsmtFinType2 | BsmtFinSF2 | BsmtUnfSF | TotalBsmtSF | Heating | HeatingQC | CentralAir | Electrical | 1stFlrSF | 2ndFlrSF | LowQualFinSF | GrLivArea | BsmtFullBath | BsmtHalfBath | FullBath | HalfBath | BedroomAbvGr | KitchenAbvGr | KitchenQual | TotRmsAbvGrd | Functional | Fireplaces | FireplaceQu | GarageType | GarageYrBlt | GarageFinish | GarageCars | GarageArea | GarageQual | GarageCond | PavedDrive | WoodDeckSF | OpenPorchSF | EnclosedPorch | 3SsnPorch | ScreenPorch | PoolArea | PoolQC | Fence | MiscFeature | MiscVal | MoSold | YrSold | SaleType | SaleCondition | SalePrice | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 60 | RL | 65.0 | 8450 | Pave | NaN | Reg | Lvl | AllPub | Inside | Gtl | CollgCr | Norm | Norm | 1Fam | 2Story | 7 | 5 | 2003 | 2003 | Gable | CompShg | VinylSd | VinylSd | BrkFace | 196.0 | Gd | TA | PConc | Gd | TA | No | GLQ | 706 | Unf | 0 | 150 | 856 | GasA | Ex | Y | SBrkr | 856 | 854 | 0 | 1710 | 1 | 0 | 2 | 1 | 3 | 1 | Gd | 8 | Typ | 0 | NaN | Attchd | 2003.0 | RFn | 2 | 548 | TA | TA | Y | 0 | 61 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | 0 | 2 | 2008 | WD | Normal | 208500 |
| 1 | 2 | 20 | RL | 80.0 | 9600 | Pave | NaN | Reg | Lvl | AllPub | FR2 | Gtl | Veenker | Feedr | Norm | 1Fam | 1Story | 6 | 8 | 1976 | 1976 | Gable | CompShg | MetalSd | MetalSd | None | 0.0 | TA | TA | CBlock | Gd | TA | Gd | ALQ | 978 | Unf | 0 | 284 | 1262 | GasA | Ex | Y | SBrkr | 1262 | 0 | 0 | 1262 | 0 | 1 | 2 | 0 | 3 | 1 | TA | 6 | Typ | 1 | TA | Attchd | 1976.0 | RFn | 2 | 460 | TA | TA | Y | 298 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | 0 | 5 | 2007 | WD | Normal | 181500 |
| 2 | 3 | 60 | RL | 68.0 | 11250 | Pave | NaN | IR1 | Lvl | AllPub | Inside | Gtl | CollgCr | Norm | Norm | 1Fam | 2Story | 7 | 5 | 2001 | 2002 | Gable | CompShg | VinylSd | VinylSd | BrkFace | 162.0 | Gd | TA | PConc | Gd | TA | Mn | GLQ | 486 | Unf | 0 | 434 | 920 | GasA | Ex | Y | SBrkr | 920 | 866 | 0 | 1786 | 1 | 0 | 2 | 1 | 3 | 1 | Gd | 6 | Typ | 1 | TA | Attchd | 2001.0 | RFn | 2 | 608 | TA | TA | Y | 0 | 42 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | 0 | 9 | 2008 | WD | Normal | 223500 |
| 3 | 4 | 70 | RL | 60.0 | 9550 | Pave | NaN | IR1 | Lvl | AllPub | Corner | Gtl | Crawfor | Norm | Norm | 1Fam | 2Story | 7 | 5 | 1915 | 1970 | Gable | CompShg | Wd Sdng | Wd Shng | None | 0.0 | TA | TA | BrkTil | TA | Gd | No | ALQ | 216 | Unf | 0 | 540 | 756 | GasA | Gd | Y | SBrkr | 961 | 756 | 0 | 1717 | 1 | 0 | 1 | 0 | 3 | 1 | Gd | 7 | Typ | 1 | Gd | Detchd | 1998.0 | Unf | 3 | 642 | TA | TA | Y | 0 | 35 | 272 | 0 | 0 | 0 | NaN | NaN | NaN | 0 | 2 | 2006 | WD | Abnorml | 140000 |
| 4 | 5 | 60 | RL | 84.0 | 14260 | Pave | NaN | IR1 | Lvl | AllPub | FR2 | Gtl | NoRidge | Norm | Norm | 1Fam | 2Story | 8 | 5 | 2000 | 2000 | Gable | CompShg | VinylSd | VinylSd | BrkFace | 350.0 | Gd | TA | PConc | Gd | TA | Av | GLQ | 655 | Unf | 0 | 490 | 1145 | GasA | Ex | Y | SBrkr | 1145 | 1053 | 0 | 2198 | 1 | 0 | 2 | 1 | 4 | 1 | Gd | 9 | Typ | 1 | TA | Attchd | 2000.0 | RFn | 3 | 836 | TA | TA | Y | 192 | 84 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | 0 | 12 | 2008 | WD | Normal | 250000 |
Id列、目的変数となるSalePrice列、特徴量が79個あり、合計で81列になります。
1train.shape
2# (1460, 81)データのクリーニング
まずは、dablを使って、簡単なデータのクリーニングをします。
1train_clean = dabl.clean(train, verbose=1)1Detected feature types:
23 float, 35 int, 43 object, 0 date, 0 other
3Interpreted as:
4continuous 19
5dirty_float 0
6low_card_int 6
7categorical 43
8date 0
9free_string 0
10useless 13
11dtype: int64データの型から適切な変換をしてくれているみたいです。
クリーニングしたデータをみてみます。
1train_clean.head()| | MSSubClass | MSZoning | LotFrontage | LotArea | Alley | LotShape | LandContour | LotConfig | LandSlope | Neighborhood | Condition1 | BldgType | HouseStyle | OverallQual | OverallCond | YearBuilt | YearRemodAdd | RoofStyle | Exterior1st | Exterior2nd | MasVnrType | MasVnrArea | ExterQual | ExterCond | Foundation | BsmtQual | BsmtCond | BsmtExposure | BsmtFinType1 | BsmtFinSF1 | BsmtFinType2 | BsmtFinSF2 | BsmtUnfSF | TotalBsmtSF | HeatingQC | CentralAir | Electrical | 1stFlrSF | 2ndFlrSF | GrLivArea | BsmtFullBath | BsmtHalfBath | FullBath | HalfBath | BedroomAbvGr | KitchenQual | TotRmsAbvGrd | Functional | Fireplaces | FireplaceQu | GarageType | GarageYrBlt | GarageFinish | GarageCars | GarageArea | PavedDrive | WoodDeckSF | OpenPorchSF | EnclosedPorch | ScreenPorch | PoolQC | Fence | MiscFeature | MoSold | YrSold | SaleType | SaleCondition | SalePrice | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | 0 | 60 | RL | 65.0 | 8450 | NaN | Reg | Lvl | Inside | Gtl | CollgCr | Norm | 1Fam | 2Story | 7 | 5 | 2003 | 2003 | Gable | VinylSd | VinylSd | BrkFace | 196.0 | Gd | TA | PConc | Gd | TA | No | GLQ | 706 | Unf | 0 | 150 | 856 | Ex | Y | SBrkr | 856 | 854 | 1710 | 1 | 0 | 2 | 1 | 3 | Gd | 8 | Typ | 0 | NaN | Attchd | 2003.0 | RFn | 2 | 548 | Y | 0 | 61 | 0 | 0 | NaN | NaN | NaN | 2 | 2008 | WD | Normal | 208500 1 | 20 | RL | 80.0 | 9600 | NaN | Reg | Lvl | FR2 | Gtl | Veenker | Feedr | 1Fam | 1Story | 6 | 8 | 1976 | 1976 | Gable | MetalSd | MetalSd | None | 0.0 | TA | TA | CBlock | Gd | TA | Gd | ALQ | 978 | Unf | 0 | 284 | 1262 | Ex | Y | SBrkr | 1262 | 0 | 1262 | 0 | 1 | 2 | 0 | 3 | TA | 6 | Typ | 1 | TA | Attchd | 1976.0 | RFn | 2 | 460 | Y | 298 | 0 | 0 | 0 | NaN | NaN | NaN | 5 | 2007 | WD | Normal | 181500 2 | 60 | RL | 68.0 | 11250 | NaN | IR1 | Lvl | Inside | Gtl | CollgCr | Norm | 1Fam | 2Story | 7 | 5 | 2001 | 2002 | Gable | VinylSd | VinylSd | BrkFace | 162.0 | Gd | TA | PConc | Gd | TA | Mn | GLQ | 486 | Unf | 0 | 434 | 920 | Ex | Y | SBrkr | 920 | 866 | 1786 | 1 | 0 | 2 | 1 | 3 | Gd | 6 | Typ | 1 | TA | Attchd | 2001.0 | RFn | 2 | 608 | Y | 0 | 42 | 0 | 0 | NaN | NaN | NaN | 9 | 2008 | WD | Normal | 223500 3 | 70 | RL | 60.0 | 9550 | NaN | IR1 | Lvl | Corner | Gtl | Crawfor | Norm | 1Fam | 2Story | 7 | 5 | 1915 | 1970 | Gable | Wd Sdng | Wd Shng | None | 0.0 | TA | TA | BrkTil | TA | Gd | No | ALQ | 216 | Unf | 0 | 540 | 756 | Gd | Y | SBrkr | 961 | 756 | 1717 | 1 | 0 | 1 | 0 | 3 | Gd | 7 | Typ | 1 | Gd | Detchd | 1998.0 | Unf | 3 | 642 | Y | 0 | 35 | 272 | 0 | NaN | NaN | NaN | 2 | 2006 | WD | Abnorml | 140000 4 | 60 | RL | 84.0 | 14260 | NaN | IR1 | Lvl | FR2 | Gtl | NoRidge | Norm | 1Fam | 2Story | 8 | 5 | 2000 | 2000 | Gable | VinylSd | VinylSd | BrkFace | 350.0 | Gd | TA | PConc | Gd | TA | Av | GLQ | 655 | Unf | 0 | 490 | 1145 | Ex | Y | SBrkr | 1145 | 1053 | 2198 | 1 | 0 | 2 | 1 | 4 | Gd | 9 | Typ | 1 | TA | Attchd | 2000.0 | RFn | 3 | 836 | Y | 192 | 84 | 0 | 0 | NaN | NaN | NaN | 12 | 2008 | WD | Normal | 250000
uselessとなっている13カラムが削除されていました。
1train_clean.shape
2# (1460, 68)削除されたカラムを確認してみます。
1set(train.columns) - set(train_clean.columns)
2# {'3SsnPorch', 'Condition2', 'GarageCond', 'GarageQual', 'Heating', 'Id', 'KitchenAbvGr', 'LowQualFinSF', 'MiscVal', 'PoolArea', 'RoofMatl', 'Street', 'Utilities'}型の検知
dablは各特徴量の型を検知することもできます。
1dabl.detect_types(train)| continuous | dirty_float | low_card_int | categorical | date | free_string | useless | |
|---|---|---|---|---|---|---|---|
| Id | False | False | False | False | False | False | True |
| MSSubClass | False | False | True | False | False | False | False |
| MSZoning | False | False | False | True | False | False | False |
| LotFrontage | True | False | False | False | False | False | False |
| LotArea | True | False | False | False | False | False | False |
| Street | False | False | False | False | False | False | True |
| Alley | False | False | False | True | False | False | False |
| LotShape | False | False | False | True | False | False | False |
| LandContour | False | False | False | True | False | False | False |
| Utilities | False | False | False | False | False | False | True |
可視化
次にdablで可視化をしていきます。
目的変数となるSalePriceを対象に可視化してみます。
1dabl.plot(train, 'SalePrice')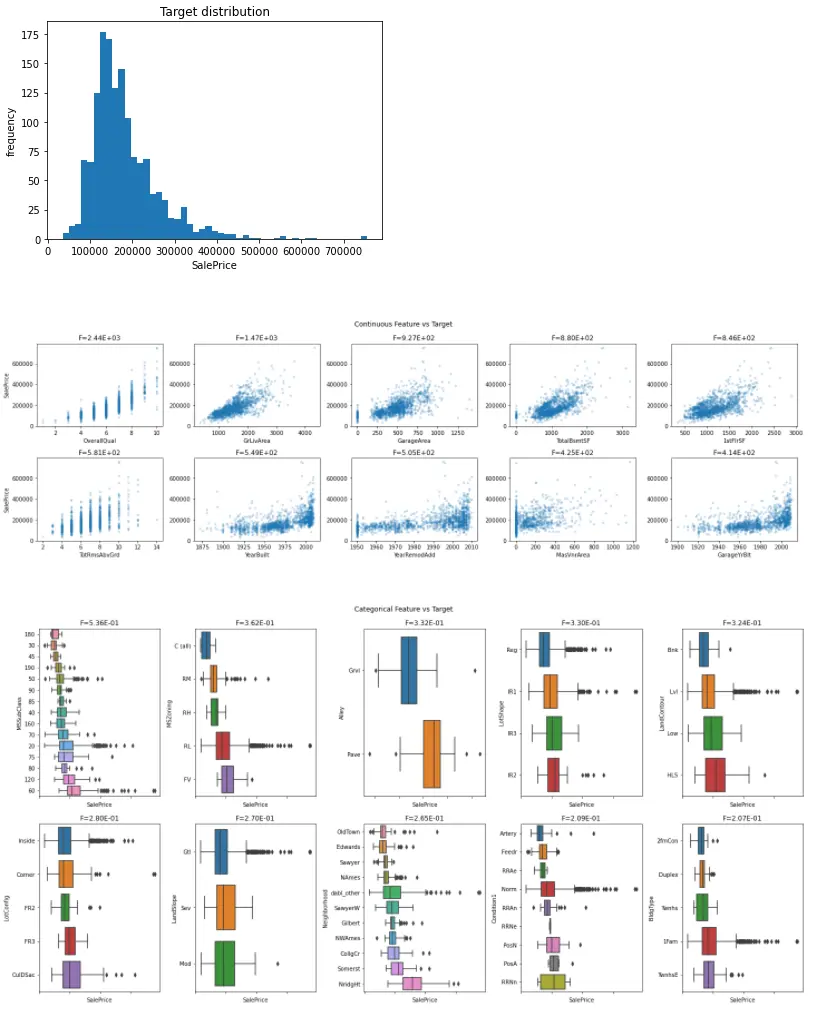
たった1行で複数のグラフを出力できました。 目的変数の分布だけでなく、数値変数、カテゴリ変数それぞれと目的変数の関係も可視化してくれています。
学習
最後はdablを使ってモデルの学習をしていきます。
1model = dabl.SimpleRegressor(random_state=0)
2X = train_clean.drop("SalePrice", axis=1)
3y = train_clean.SalePrice
4model.fit(X, y)1Running DummyRegressor()
2r2: -0.013 neg_mean_squared_error: -6332779880.688
3=== new best DummyRegressor() (using r2):
4r2: -0.013 neg_mean_squared_error: -6332779880.688
5
6Running DecisionTreeRegressor(max_depth=1)
7r2: 0.450 neg_mean_squared_error: -3448402932.386
8=== new best DecisionTreeRegressor(max_depth=1) (using r2):
9r2: 0.450 neg_mean_squared_error: -3448402932.386
10
11Running DecisionTreeRegressor(max_depth=5)
12r2: 0.755 neg_mean_squared_error: -1534411175.119
13=== new best DecisionTreeRegressor(max_depth=5) (using r2):
14r2: 0.755 neg_mean_squared_error: -1534411175.119
15
16Running Ridge(alpha=10)
17r2: 0.844 neg_mean_squared_error: -1007546259.414
18=== new best Ridge(alpha=10) (using r2):
19r2: 0.844 neg_mean_squared_error: -1007546259.414
20
21Running Lasso(alpha=10)
22r2: 0.714 neg_mean_squared_error: -1926613454.120
23
24Best model:
25Ridge(alpha=10)
26Best Scores:
27r2: 0.844 neg_mean_squared_error: -1007546259.414
28SimpleRegressor(random_state=0)複数のモデルで学習しスコアを比較して、最もスコアがよかったモデルを返してくれます。
まとめ
- dablは教師あり学習の基本的なタスクを簡単にできる
- 可視化が便利
参考
- Welcome to dabl, the Data Analysis Baseline Library — dabl documentation
- dabl/dabl: Data Analysis Baseline Library
- Automating Data Science with dabl | Data Science and Machine Learning | Kaggle
\ この記事が役に立ったと思ったら、サポートお願いします! /

関連記事
【初心者】0から始めるkaggle入門

Keras Tunerでハイパーパラメータチューニング


