kaggleやSIGNATEのテーブルデータコンペでとりあえずやること
はじめに
kaggleやSIGNATEのテーブルデータのコンペに参加したときにとりあえずやってみることをまとめました。
とりあえずやってみることなので、コンペによってはやらなくていいものも含まれている可能性があります。また、この他にもやったことがいいことはあるかと思いますので、都度更新したいと思います。
今回、サンプルとしているデータはkaggleのタイタニックコンペと住宅価格予測コンペのデータになります。可視化している画像については特徴量やデータの数によって、ちょうどいいサイズが異なるかと思うので都度調整してください。
準備
まずは必要なライブラリとデータのインポートを行います。
ライブラリのインポートです。
1import pandas as pd
2import lightgbm as lgb
3from sklearn.preprocessing import LabelEncoder
4from sklearn.model_selection import train_test_split
5
6import matplotlib.pyplot as plt
7import seaborn as sns
8sns.set()学習データとテストデータを読み込みます。
1train = pd.read_csv('../input/titanic/train.csv')
2test = pd.read_csv('../input/titanic/test.csv')データ数と特徴量の数を確認
学習データとテストデータの数、特徴量の数を確認します。
1print('train data: {}'.format(train.shape[0]))
2print('test data: {}'.format(test.shape[0]))
3print('features: {}'.format(test.shape[1]))1train data: 891
2test data: 418
3features: 11データをみてみる
データの中身やカラムなどなんとなくのデータのイメージをつかむために、とりあえずデータの上位10個を見てみます。
1train.head(10)1test.head(10)カラムと型の確認
カラム名とそれぞれの型を確認します。
1train.dtypes1PassengerId int64
2Survived int64
3Pclass int64
4Name object
5Sex object
6Age float64
7SibSp int64
8Parch int64
9Ticket object
10Fare float64
11Cabin object
12Embarked object
13dtype: objectより詳しい情報をみるときは以下のコードも使えます。
1train.info()1<class 'pandas.core.frame.DataFrame'>
2RangeIndex: 891 entries, 0 to 890
3Data columns (total 12 columns):
4 # Column Non-Null Count Dtype
5--- ------ -------------- -----
6 0 PassengerId 891 non-null int64
7 1 Survived 891 non-null int64
8 2 Pclass 891 non-null int64
9 3 Name 891 non-null object
10 4 Sex 891 non-null object
11 5 Age 714 non-null float64
12 6 SibSp 891 non-null int64
13 7 Parch 891 non-null int64
14 8 Ticket 891 non-null object
15 9 Fare 891 non-null float64
16 10 Cabin 204 non-null object
17 11 Embarked 889 non-null object
18dtypes: float64(2), int64(5), object(5)
19memory usage: 83.7+ KB欠損値の確認
学習データとテストデータに欠損値が含まれているか確認します。
欠損値がある場合は、どう対処するか考える必要があります。簡単な対応は後ほど説明します。
1train.isnull().sum()1PassengerId 0
2Survived 0
3Pclass 0
4Name 0
5Sex 0
6Age 177
7SibSp 0
8Parch 0
9Ticket 0
10Fare 0
11Cabin 687
12Embarked 2
13dtype: int641test.isnull().sum()1PassengerId 0
2Pclass 0
3Name 0
4Sex 0
5Age 86
6SibSp 0
7Parch 0
8Ticket 0
9Fare 1
10Cabin 327
11Embarked 0
12dtype: int64ターゲットの分布
予測するターゲットの分布を確認します。
分類問題ならそれぞれのクラスの数をカウントします。
1sns.countplot(x='Survived', data=train)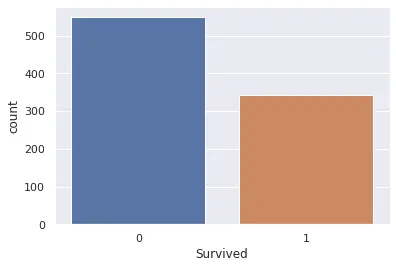
回帰問題ならヒストグラムで分布を可視化します。
1sns.displot(train['SalePrice'], height=10)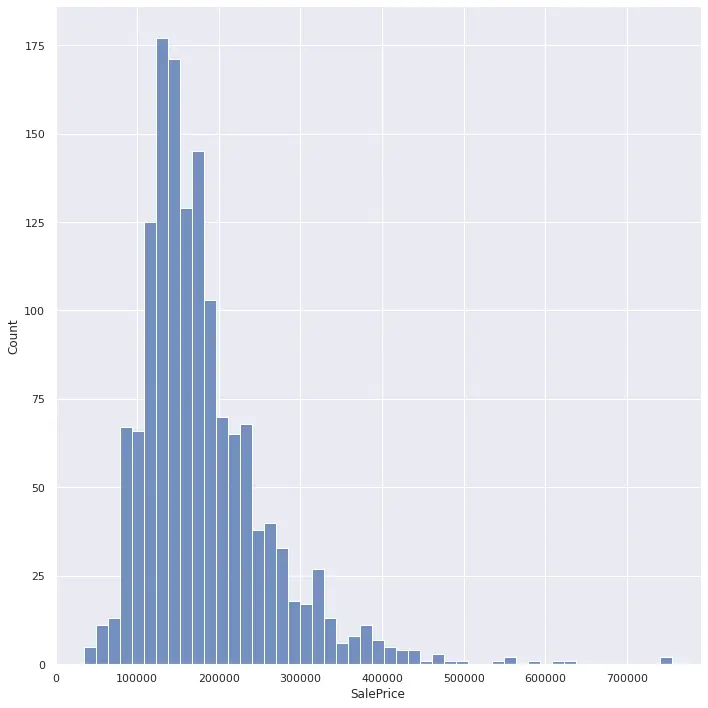
カテゴリデータの分布
カテゴリデータの分布を確認します。
偏った分布のカテゴリデータがないか、学習データやテストデータにしかないクラスがないか確認します。
1cat_cols = ['Pclass', 'Sex', 'Embarked']
2fig, axes = plt.subplots(len(cat_cols), 2, figsize=(15, 20))
3for i, c in enumerate(cat_cols):
4 sns.countplot(x=c, data=train, ax=axes[i,0]).set(title=c+' train')
5 sns.countplot(x=c, data=test, ax=axes[i,1]).set(title=c+' test')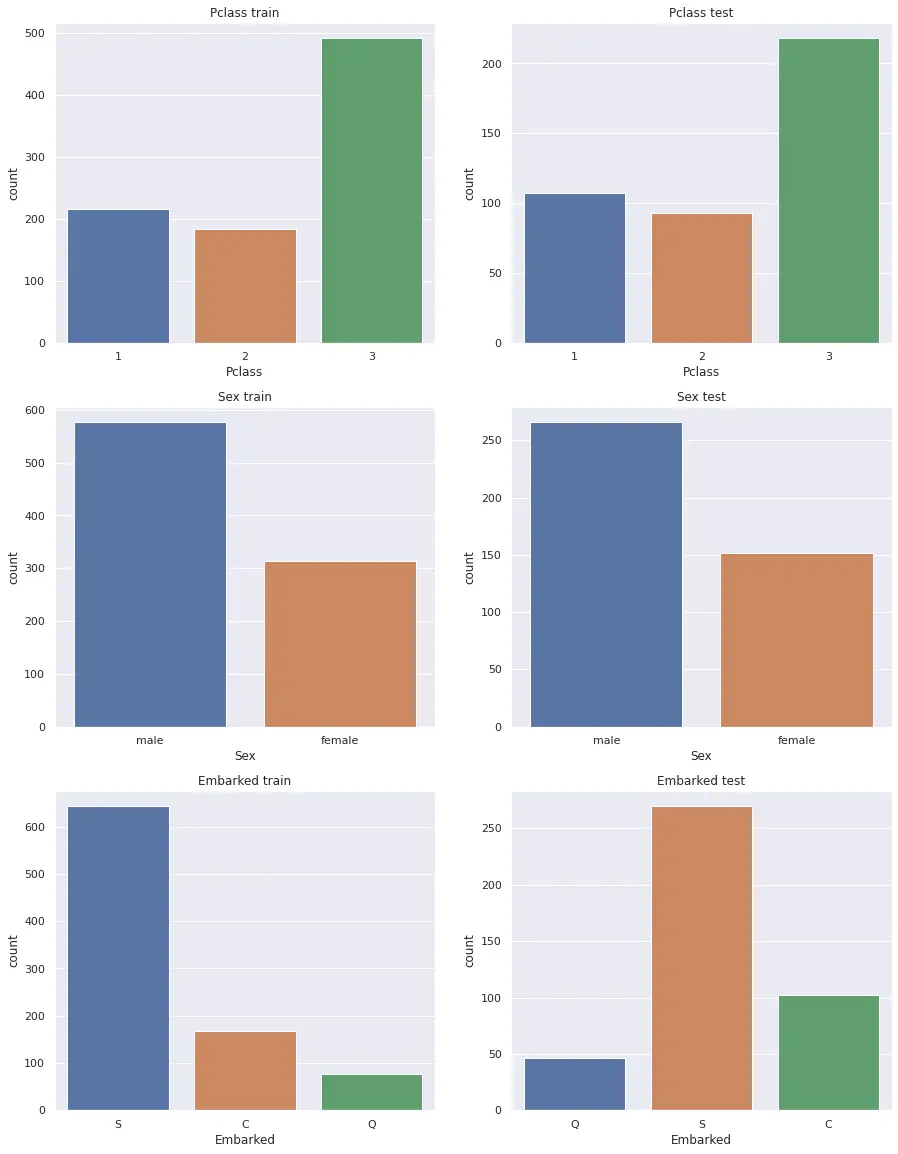
ペアプロットとヒストグラム
ペアプロットを確認します。
各特徴量の組み合わせでの散布図とヒストグラムが表示されます。
特徴量が多いと実行に時間がかかるので、多すぎる場合は必要な特徴量を選択して実行するのがいいです。
1sns.pairplot(train, hue='Survived', diag_kind='hist', palette={0: 'red', 1: 'blue'})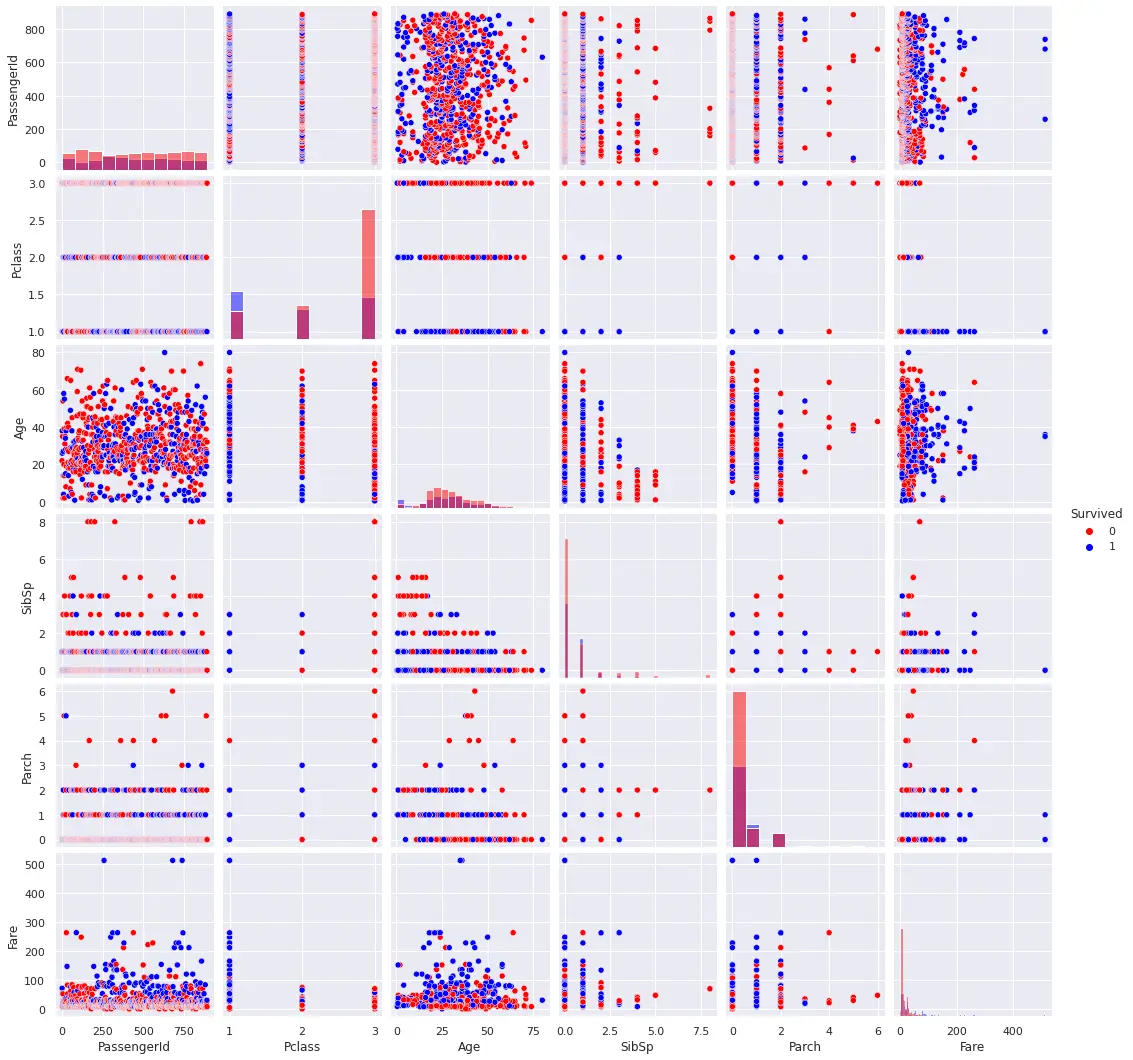
特徴量の選択はvarsで指定します。
1sns.pairplot(train, hue='Survived', diag_kind='hist', palette={0: 'red', 1: 'blue'}, vars=['Age', 'Fare'], size=5)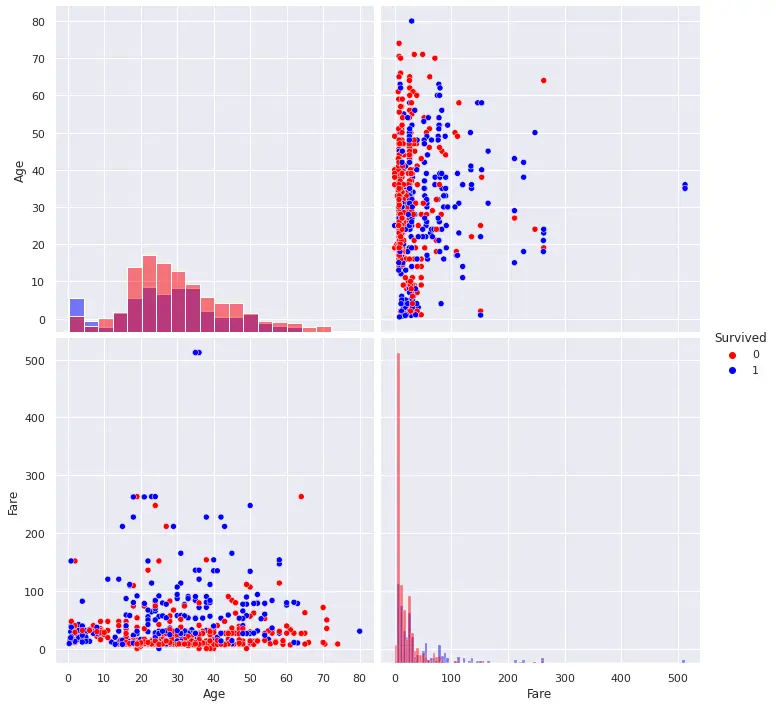
分類問題でクラスごとに色分けしたいヒストグラムをみたい場合は以下のようにします。
1sns.displot(train, x="Age", hue="Survived", multiple="stack")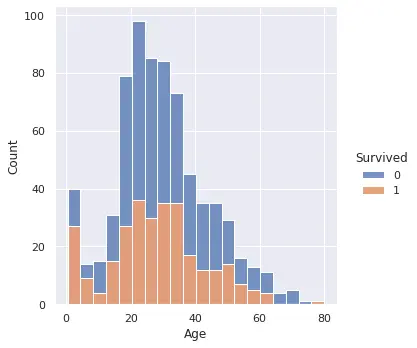
ヒートマップ
ヒートマップで特徴量同士の相関を確認します。
1plt.subplots(figsize=(10,10))
2sns.heatmap(train.corr(), annot=True)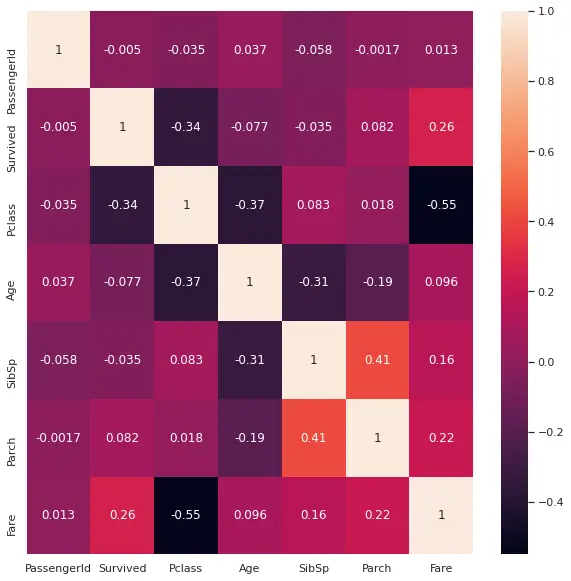
欠損値の扱い
欠損値の扱いを決めます。
欠損値をどう扱うかは色々試す必要があるかと思いますが、最初は簡単な方法で処理します。
そのまま扱う場合は特に何もしません。
取り除く
- 欠損値があるデータ(行)を削除
1train.dropna()- 欠損値のある特徴量(列)を削除
1train.dropna(axis=1)- 特定の列に欠損値があるデータを削除
1train.dropna(subset=['Age'])埋める
- 欠損値を全て同じ値で置換
1train.fillna(0)- 列によって置換する値を変える
1train.fillna({'Age': 20, 'Cabin': 0})カテゴリデータの変換
カテゴリデータの変換もいくつか方法があるかと思いますが、最初は簡単な方法で変換します。
one-hot encoding
cat_oh_colsに変換するカテゴリデータのカラム名を持つようにしています。
1all_cat = pd.concat([train[cat_oh_cols], test[cat_oh_cols]])
2all_cat = pd.get_dummies(all_cat, columns=cat_oh_cols)
3
4train = pd.concat([train, all_cat.iloc[:train.shape[0], :].reset_index(drop=True)], axis=1)
5test = pd.concat([test, all_cat.iloc[train.shape[0]:, :].reset_index(drop=True)], axis=1)label encoding
cat_le_colsに変換するカテゴリデータのカラム名を持つようにしています。
1for c in cat_le_cols:
2 le = LabelEncoder()
3 le.fit(train[c])
4 train[c] = le.transform(train[c])
5 test[c] = le.transform(test[c])LightGBMで学習
一通りデータの確認ができたらLightGBMでモデルを学習させてみます。
問題設定によってはパラメータの変更が必要になります。
ここでは二値分類を想定しています。
1target = ['Survived']
2features = list(set(train.columns) - set(target))
3
4X = train[features].values
5y = train[target].values.reshape(-1)
6X_test = test[features].values
7
8X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3, random_state=0)
9
10lgb_train = lgb.Dataset(X_train, y_train)
11lgb_eval = lgb.Dataset(X_valid, y_valid)
12
13params = {
14 'objective': 'binary',
15}
16num_round = 100
17
18model = lgb.train(
19 params,
20 lgb_train,
21 valid_sets=lgb_eval,
22 num_boost_round=num_round,
23 verbose_eval=10
24)特徴量の重要度
LightGBMでモデルを学習させると各特徴量の重要度を求めることができるので可視化してみます。
1importance = pd.DataFrame()
2importance['feature'] = features
3importance['importance'] = model.feature_importance(importance_type='gain')
4
5sns.barplot(x='importance', y='feature', data=importance.sort_values(by='importance', ascending=False))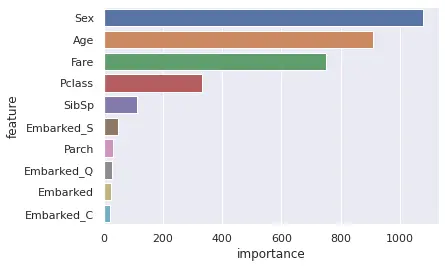
参考
- Welcome to LightGBM’s documentation! — LightGBM 3.2.1.99 documentation
- Visualizing distributions of data — seaborn 0.11.1 documentation
- seaborn.heatmap — seaborn 0.11.1 documentation
- 【随時更新】Kaggleテーブルデータコンペできっと役立つTipsまとめ - ML_BearのKaggleな日常


\ この記事が役に立ったと思ったら、サポートお願いします! /

関連記事


kaggleでよく使う交差検証テンプレ(Keras向け)

手軽にデータ分析ができるdablを使ってみた

