はじめに
時系列データを簡単に予測できるProphetについて、基本的な使い方と実際に使ってみた具体例を紹介したいと思います。
Prophetとは
Prophetとは、Facebookが開発した時系列データの予測ができるライブラリです。
外れ値や欠損値があっても簡単に精度のいいモデルを作成できます。また、パラメータを調整することでよりいいモデルの作成も可能になります。
どのように予測しているか
どのように予測しているのか簡単に説明します。
トレンドや年単位や週単位などの周期性、休日の影響に基づいて時系列データを予測するモデルになります。
予測結果は以下の式から求められます。
基本的な使い方
Prophetの基本的な使い方を紹介していきます。
ここではAirline Passengersのデータを利用します。今回はkaggleでアップされていたデータを利用しています。

Air Passengers
Number of air passengers per month
インストール
まずはProphetをインストールします。
1pip install Prophet準備
まずは、必要なライブラリをインポートします。
1import pandas as pd
2from prophet import Prophet
3
4import seaborn as sns
5sns.set()利用データ
利用するデータを読み込みます。
1data = pd.read_csv('../input/air-passengers/AirPassengers.csv')以下のような1949年1月から1960年12月の飛行機の乗客データになっています。
| Month | #Passengers | |
|---|---|---|
| 0 | 1949-01 | 112 |
| 1 | 1949-02 | 118 |
| 2 | 1949-03 | 132 |
| 3 | 1949-04 | 129 |
| 4 | 1949-05 | 121 |
| ... | ... | ... |
| 139 | 1960-08 | 606 |
| 140 | 1960-09 | 508 |
| 141 | 1960-10 | 461 |
| 142 | 1960-11 | 390 |
| 143 | 1960-12 | 432 |
どのようなデータか可視化してみます。
1sns.lineplot(x="Month", y="#Passengers", data=data)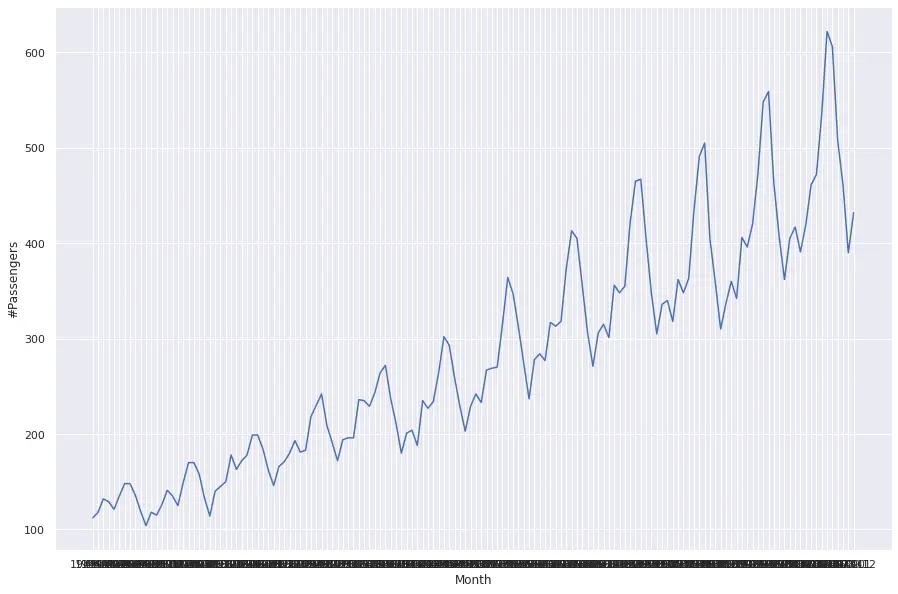
学習データの準備
学習データの準備をしていきます。
Prophetで学習させるデータは時系列を表すdsカラムと予測する対象となるyカラムが必要になります。
データの形としては今のままでいいですが、カラム名が適切ではないので、カラム名の変更をします。
1data.columns = ['ds', 'y']また、学習データとテストデータを分割します。ここでは、最後の12ヶ月をテストデータとしています。
1test_length = 12
2train = data.iloc[:-test_length]
3test = data.iloc[-test_length:]学習
学習データの準備ができたので、そのデータを用いてモデルの学習をします。
1model = Prophet(seasonality_mode='multiplicative')
2model.fit(train)パラメータ
モデルには以下のパラメータが設定可能です。問題により適切なパラメータを設定することで精度が向上します。
- growth: トレンドを表す関数(線形かロジスティック曲線)
- changepoints: トレンドの変化点のリスト
- n_changepoints: トレンドの変化点の数
- changepoint_range: トレンドの変化点を推測する幅
- yearly_seasonality: 年単位の周期性を考慮するか
- weekly_seasonalityJ: 週単位の周期性を考慮するか
- daily_seasonality: 日単位の周期性を考慮するか
- holidays: 休日
- seasonality_mode: 周期性の傾向
- seasonality_prior_scale: 周期性の強さを表すパラメータ
- holidays_prior_scale: 休日の強さを表すパラメータ
- changepoint_prior_scale: トレンドの変化点の強さを表すパラメータ
- mcmc_samples: MCMC法(マルコフ連鎖モンテカルロ法)のサンプル数
- interval_width: 誤差の範囲の広さ
- uncertainty_samples: 誤差を推測するためのサンプル数
- stan_backend: バックエンドの指定
以下のようにパラメータの指定ができます。下記は全てデフォルト値になっています。
1params = {'growth': 'linear',
2 'changepoints': None,
3 'n_changepoints': 25,
4 'changepoint_range': 0.8,
5 'yearly_seasonality': 'auto',
6 'weekly_seasonality': 'auto',
7 'daily_seasonality': 'auto',
8 'holidays': None,
9 'seasonality_mode': 'additive',
10 'seasonality_prior_scale': 10.0,
11 'holidays_prior_scale': 10.0,
12 'changepoint_prior_scale': 0.05,
13 'mcmc_samples': 0,
14 'interval_width': 0.80,
15 'uncertainty_samples': 1000,
16 'stan_backend': None}
17
18model = Prophet(**params)パラメータチューニングする場合は以下のパラメータが多いです。
- changepoint_prior_scale
- seasonality_prior_scale
- holidays_prior_scale
- seasonality_mode
- changepoint_range
予測
学習が完了したらテストデータで予測します。
make_future_dataframeで学習データの期間にテストデータ(未来のデータ)を追加したDataFrameを作成します。このデータを使って予測します。
1future = model.make_future_dataframe(periods=test_length, freq='M')
2pred = model.predict(future)予測した結果は以下のようになります。評価指標を計算する場合はyhatカラムを利用します。
| ds | trend | yhat_lower | yhat_upper | trend_lower | trend_upper | multiplicative_terms | multiplicative_terms_lower | multiplicative_terms_upper | yearly | yearly_lower | yearly_upper | additive_terms | additive_terms_lower | additive_terms_upper | yhat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1949-01-01 | 115.603966 | 91.865217 | 116.958190 | 115.603966 | 115.603966 | -0.101135 | -0.101135 | -0.101135 | -0.101135 | -0.101135 | -0.101135 | 0.0 | 0.0 | 0.0 | 103.912403 |
| 1 | 1949-02-01 | 117.275019 | 86.208456 | 111.255977 | 117.275019 | 117.275019 | -0.154216 | -0.154216 | -0.154216 | -0.154216 | -0.154216 | -0.154216 | 0.0 | 0.0 | 0.0 | 99.189377 |
| 2 | 1949-03-01 | 118.784358 | 107.379400 | 131.664532 | 118.784358 | 118.784358 | 0.002721 | 0.002721 | 0.002721 | 0.002721 | 0.002721 | 0.002721 | 0.0 | 0.0 | 0.0 | 119.107520 |
| 3 | 1949-04-01 | 120.455412 | 103.425669 | 129.164002 | 120.455412 | 120.455412 | -0.033256 | -0.033256 | -0.033256 | -0.033256 | -0.033256 | -0.033256 | 0.0 | 0.0 | 0.0 | 116.449565 |
| 4 | 1949-05-01 | 122.072561 | 106.650815 | 131.868761 | 122.072561 | 122.072561 | -0.027357 | -0.027357 | -0.027357 | -0.027357 | -0.027357 | -0.027357 | 0.0 | 0.0 | 0.0 | 118.733027 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 139 | 1960-07-31 | 464.860836 | 571.806814 | 598.207529 | 464.129166 | 465.490336 | 0.257393 | 0.257393 | 0.257393 | 0.257393 | 0.257393 | 0.257393 | 0.0 | 0.0 | 0.0 | 584.512761 |
| 140 | 1960-08-31 | 467.660516 | 474.601698 | 499.457627 | 466.735673 | 468.483337 | 0.041049 | 0.041049 | 0.041049 | 0.041049 | 0.041049 | 0.041049 | 0.0 | 0.0 | 0.0 | 486.857711 |
| 141 | 1960-09-30 | 470.369885 | 414.832248 | 440.271254 | 469.248001 | 471.331630 | -0.091353 | -0.091353 | -0.091353 | -0.091353 | -0.091353 | -0.091353 | 0.0 | 0.0 | 0.0 | 427.400268 |
| 142 | 1960-10-31 | 473.169565 | 360.064275 | 386.413159 | 471.812173 | 474.293732 | -0.210581 | -0.210581 | -0.210581 | -0.210581 | -0.210581 | -0.210581 | 0.0 | 0.0 | 0.0 | 373.529040 |
| 143 | 1960-11-30 | 475.878934 | 411.538263 | 436.644966 | 474.320539 | 477.207354 | -0.108360 | -0.108360 | -0.108360 | -0.108360 | -0.108360 | -0.108360 | 0.0 | 0.0 | 0.0 | 424.312896 |
可視化
予測した結果を可視化します。 Prophetではmatplotlibなどのライブラリを利用しなくても可視化できます。
黒い点が学習データの実際の値になります。
1pred_plot = model.plot(pred)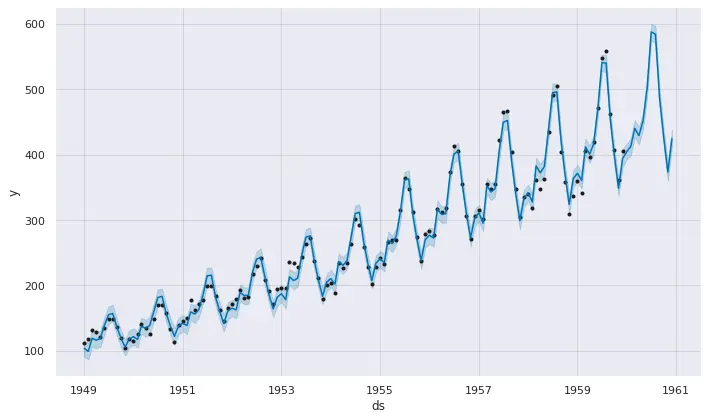
plot_componentsを使うとトレンドや周期性の可視化もできます。
1component_plot = model.plot_components(pred)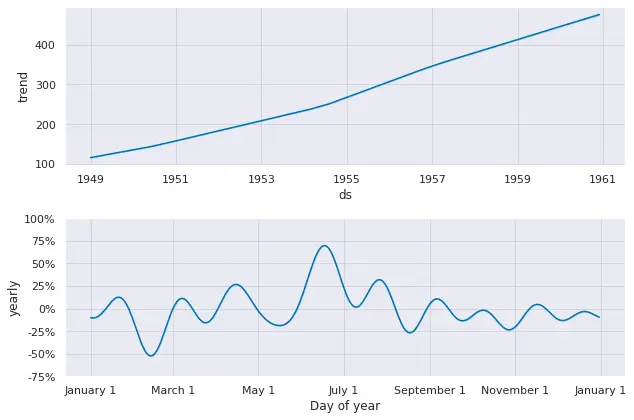
まとめ
- Prophetを使うと時系列データを簡単に予測できる
参考
- Prophet | Forecasting at scale.
- Forecasting at scale [PeerJ Preprints]
- Quick Start | Prophet
- Prophet統計モデル概要 | 西陣に住むデータ分析屋のブログ
- Prophet入門【理論編】Facebookの時系列予測ツール
\ この記事が役に立ったと思ったら、サポートお願いします! /

関連記事

機械学習で使われる評価関数まとめ

NeuralProphetで時系列データ予測

【入門機械学習】動かして理解する人工知能・機械学習・ディープラーニングの違い

